SPARQL 1.1について
このページでは、SPARQL 1.1に対応したエンドポイントで可能になった検索方法について説明します。
「SPARQLについて」に記載している検索はSPARQL1.1でも使用可能です。より新しいエンドポイントであるSPARQL1.1では、SPARQL1.0よりも多くの結果を一度に得られるため、SPARQL1.1による検索をお勧めします。
便利な検索事例については、「SPARQL検索クエリ例」ページに掲載しています。
1. SPARQL 1.1に対応したエンドポイント
https://id.ndl.go.jp/auth/ndla/sparql- Web NDL Authorities SPARQL API仕様書 2023年3月31日(PDF: 478KB)
- Web NDL Authorities SPARQL API Specifications 2023-03-31(PDF: 498KB)
- クエリ例の表示
- テーブル形式、グラフ図(一部対応※)、応答内容の表示
※DESCRIBEクエリ、CONSTRUCTクエリ の場合にグラフ図を表示。またSEL ECTクエリで変数が?s ?p ?oである場合にグラフ図を切り替え表示可能。
- クエリ作成時の入力補助
2. プロパティパスを用いる
SPARQL 1.1では、複数のプロパティを連結した「パス構文」をグラフパターンの述語部に記述できます。これを用いるとSPARQL 1.0では必要だった中間ノードを省略して簡潔なクエリにまとめることが可能になります。
2-1. 簡潔なパス記述:(例1)個人名典拠の関連名称(別名)
たとえば、氏名(foaf:name)が「中島梓」である典拠の関連名称(別名)(ndl:anotherName)にあたる典拠を調べ、その氏名を取り出すためには、図1のようなグラフパターンを用います。

SPARQL 1.0では3つの中間ノードを変数または空白ノードとして示す必要がありますが、SPARQL 1.1ではプロパティを「/」で連結した「パス」として簡潔に記述できます。
図1のグラフパターンを、プロパティパスを用いて記述したクエリは、以下のとおりとなります。
2-2. プロパティの反復:(例2)件名標目の下位語の下位語
プロパティパスは、パスに含まれるプロパティをすべて列挙しなくても、反復を示す「+」などの記号を用いて表現することができます。たとえば「件名標目「歴史」の下位語」または「「歴史」の下位語の下位語」のように、「歴史」の下位の概念にあたる件名標目をすべて調べるクエリを考えてみます。グラフパターンで表すと、図2のようになります。
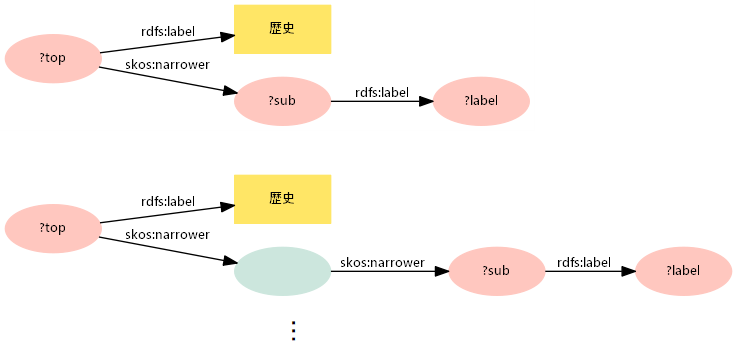
SPARQL 1.0では、想定されるパターンをすべて列挙する必要があり、あらかじめ階層の深さが分からないと検索できません。一方、SPARQL 1.1では、反復記号「+」を用いた「skos:narrower+」というプロパティパスにより、この検索を実現できます。
「+」はプロパティの「1回以上」の反復を表します。「0回以上」を表す「*」をパスに用いると、「skos:narrower」が0回、すなわち下位語を持たないもの(この例でいえば「歴史」)も検索結果に含めることができます。
2-3. プロパティのOR:(例3)名称/タイトルまたは別名/別タイトル
プロパティAとプロパティBを「|」で連結して「A | B」と記述すると、AまたはBのいずれかを持つグラフパターンを一度に表現できます。()で囲むと、さらに他のプロパティをパスとして連結可能です。たとえば図3のグラフパターンは、「個人名典拠の名称/タイトル(xl:prefLabel)または別名/別タイトル(xl:altLabel)にあたる名前」を示しています。
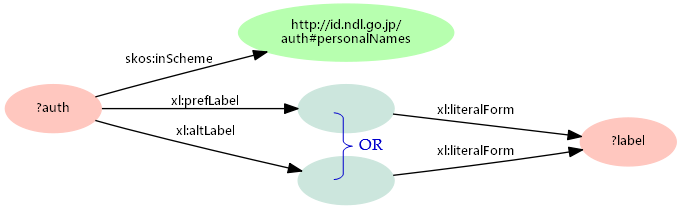
プロパティパスを用いると、「名称/タイトルまたは別名/別タイトル」(図3の「OR」になっている部分)を「(xl:prefLabel|xl:altLabel)/xl:literalForm」と記述できます。名称/タイトルまたは別名/別タイトルの名字が「西郷」であるものを調べる場合、このパスを用いれば、絞り込み条件(FILTER)は1つですみます。
3. サブクエリ
SPARQL 1.1では、1つのクエリの結果セットを利用して別のクエリを実行するサブクエリの機能が導入されました。これはSELECT句を入れ子にしたクエリとして記述します。内側のSELECT句がサブクエリとなって先に実行され、その結果を用いて外側のSELECT句が実行されます。
3-1. (例4)件名標目とその上位語に付与されている代表分類記号の数
たとえば
- 日本十進分類法(NDC)第10版の代表分類記号が4つ以上付与されている件名標目を選び、
- その上位語の件名標目にNDC10の代表分類記号がいくつ付与されているか調べる
というクエリを考えてみます。このクエリを表したのが、図4です。
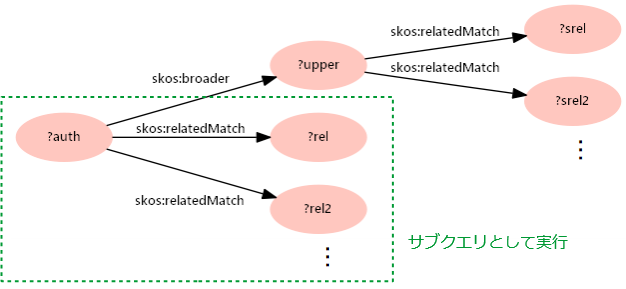
上記のクエリの場合は1.がサブクエリとなり、その結果を元に2.のクエリを実行することになります。1.の「4つ以上」という条件はHAVING句によって示します。
3-2. (例5)上位語の件数ごとの件名標目の数
今度は
- 件名標目を、その上位語の件数ごとに分け、
- 件数ごとに件名標目がいくつあるかを調べる
というクエリを考えてみます。この場合、グラフパターンによる検索は1.のサブクエリだけで、2.はその集計結果を用いて別の集計を行うクエリとなります。
サブクエリは、内側のクエリ結果すべてに対して外側のクエリを実行するので、非常に高負荷なクエリとなってしまう恐れがあります。内側のクエリ結果が多い場合、それに伴って負荷が高くなりますので、ご注意ください。
4. 否定表現と変数割り当て
NOT EXISTSを用いた否定条件の表現と、BINDを用いた変数への値の割り当てを紹介し、これらを組み合わせたやや複雑な応用例を示します。
4-1. 否定:(例6)別名/別タイトルを持たない典拠
SPARQL 1.1ではNOT EXISTSを用いて「あるパターンが存在しない」という条件(FILTER)を加えることができます。たとえば「別名/別タイトル」を持たない典拠データの名称/タイトルを調べたい場合は、典拠データの名称/タイトル(xl:prefLabel)を得るグラフパターンに、別名/別タイトル(xl:altLabel)を否定する条件を加えます。
4-2. 変数割り当て:(例7)個人名典拠(名称/タイトル)で出現頻度の高い名字トップ10
SPARQL 1.0では、変数はグラフパターン中のノードまたはアーク(プロパティ)に対応する値にしか用いることができませんでしたが、SPARQL 1.1ではBINDによって任意の値を変数に割り当てることができます。
たとえば、個人名典拠の名称/タイトルは姓名がコンマおよびスペースで区切られているので、検索した典拠データから名字を調べる(関数strbeforeを用いてコンマの前の文字列を取得する)ことが可能です。これをグラフパターンで示すと、図5のようになります。
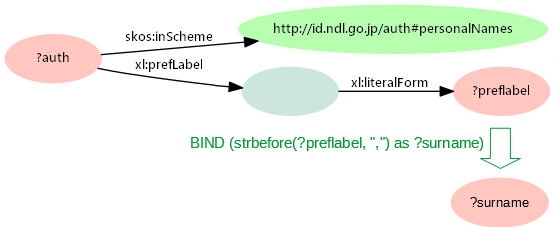
この結果を変数に割り当てて、個人名典拠の名称/タイトルに出現する頻度の高い名字トップ10をリストアップできます。
クエリにすると、以下のとおりとなります。
4-3. 否定と割り当ての応用:(例8)代表分類記号がNDC第9版と第10版で変わった件名標目
否定表現と変数割り当てを組み合わせることで「NDC第9版(NDC9)と第10版(NDC10)で、第二次区分(綱目)以下が異なる代表分類記号が付与されている件名標目を調べる」といったクエリを記述できます。複雑なので、順を追って組み立ててみましょう。
Step 1: まず典拠データに付与されているNDC9とNDC10の分類記号(skos:relatedMatch)を調べます。分類記号はNDCだけでなく国立国会図書館分類表(NDLC)もあるので、その中からNDC9とNDC10だけを、URIの正規表現によって絞り込みます。
SELECT ?auth ?label ?ndc9 ?ndc10 WHERE {
?auth rdfs:label ?label;
skos:relatedMatch ?rel;
skos:relatedMatch ?rel2.
FILTER (regex(str(?rel), "^http://id.ndl.go.jp/class/ndc9/"))
FILTER (regex(str(?rel2), "^http://id.ndl.go.jp/class/ndc10/"))
}
Step 2: 変数?relと?rel2の値はURIなので、ここから分類記号のみを取り出して(関数strafterを用いて「ndc9/」と「ndc10/」の後の文字列をそれぞれ取得する)、別の変数にそれぞれ割り当てます。
BIND (strafter(str(?rel), "ndc9/") as ?ndc9)
BIND (strafter(str(?rel2), "ndc10/") as ?ndc10)
Step 3: 「NDC9とNDC10の代表分類記号が変わった」ということは「ある典拠のNDC9と分類記号が同じであるNDC10が、同一典拠のskos:relatedMatchの値にない」と言い換えることができます。この条件に該当する典拠データを調べるために、
- 「NDC9の分類記号をNDC10の基底URI (http://id.ndl.go.jp/class/ndc10/)と組み合わせた値(つまりNDC9と分類記号が同じであるNDC10)」を変数
?ndc9as10として割り当て(BIND)、 - その変数が
skos:relatedMatchの目的語になるパターン(以下“9as10パターン”)にはマッチしない(NOT EXISTS)というFILTERを設定する
という手順を追加します。
BIND (IRI(concat("http://id.ndl.go.jp/class/ndc10/", ?ndc9)) as ?ndc9as10)
FILTER NOT EXISTS {?auth skos:relatedMatch ?ndc9as10}
Step 4: 典拠の代表分類記号がNDC9、NDC10それぞれ1つである場合は以上の条件で「NDC9とNDC10の代表分類記号が変わった」かどうかを調べることができます。しかし同じ分類表の分類記号が複数付与されている場合は、さらに組み合わせの検討が必要です。
たとえば件名標目「テレビドラマ」に対するNDC9の778.8(テレビ演劇.放送劇)と901.27(シナリオ.放送ドラマ)や、件名標目「クイズ」に対するNDC9の031.7(クイズ集.なぞなぞ集)と798(室内娯楽)などがその例です。
ここで「テレビドラマ」はNDC10も同じ分類記号(778.8と901.27)が付与されているので、上記による比較で問題ありません(どの組み合わせでも“9as10パターン”にマッチするため、FILTERで却下される=代表分類記号は変わっていない)。一方、「クイズ」ではNDC9の798がNDC10で798.3に変わっています。このときの上記クエリのフィルタ結果を表にして考えると、次のようになります(「対NDC10」は、「クイズ」の2つのNDC10のうち、Step 2のパターンで?ndc10にマッチしなかった方の値)。
| # | ?ndc9 | ?ndc10 | 対NDC10 | フィルタ | 判定が正しいかどうか |
|---|---|---|---|---|---|
| 1 | 031.7 | 031.7 | 798.3 | 却下 | ○=?ndc10が?ndc9as10と一致 |
| 2 | 031.7 | 798.3 | 031.7 | 却下 | ○=対NDC10が?ndc9as10と一致 |
| 3 | 798 | 798.3 | 031.7 | パス | ○=NDC9とNDC10で代表分類記号変更 |
| 4 | 798 | 031.7 | 798.3 | パス | ×=?ndc10を?ndc9の代表分類記号変更と誤判定 |
フィルタの結果は、Step 3の方法で生成した?ndc9as10(分類記号は?ndc9と同じ)が
?ndc10または「対NDC10」のいずれかに一致すれば、“9as10パターン”にマッチ=却下- いずれにも一致しなければ“9as10パターン”にはマッチせず、
NOT EXISTSが成立=パス
となっています。Step 3では、これをパスすれば?ndc9と?ndc10の組み合わせが「NDC9とNDC10の代表分類記号が変わった」ものに当たるようにと、条件を考えました。
表を見ると、正しく判定され、NDC9とNDC10の違いとしてフィルタをパスしたのは、《組み合わせ#3》の798→798.3だけです。上の条件だけでは、《組み合わせ#4》も?ndc9as10の798が?ndc10の031.7とも「対NDC10」の798.3とも一致しない、すなわち“9as10パターン”にマッチせず、NOT EXISTSが成立してパスしてしまうのです。
Step 5: そこで、Step 4をパスしたNDC9とNDC10の第一次区分(類目)を比較し、類目が同じ場合のみNDC9とNDC10との違いと考えることにします。このために、NDC9とNDC10の1桁目が一致するという条件(FILTER)をさらに追加します(注)。
FILTER (substr(?ndc9, 1, 1) = substr(?ndc10, 1, 1))
以上のステップをまとめたものが、次のクエリ例です。
(注)なお、NDC9とNDC10の類目が同じ場合でも、すべてのフィルタをパスした組み合わせがNDC9とNDC10の違いではないことがあります。
たとえば件名標目「興行」にはNDC9の760.69(音楽堂.音楽会.音楽興行)と770.9(興行.検閲.宣伝.看板.入場料)がそれぞれ付与されており、これがNDC10では760.9(音楽産業)と770.9となっています。このとき、Step 4までの手順では760.69→760.9(正しい《組み合わせA》)だけでなく、760.69→770.9(正しくない《組み合わせB》)もフィルタをパスしてしまうのは「クイズ」の例と同じです。ところが「興行」の場合は、《組み合わせB》の第一次区分(類目)が同じであるため、Step 5のフィルタでも取り除くことができません。
このように、1つの件名標目に同じ類目(ここでは7類)のNDC9が複数付与されている場合、類目だけでは正確な区別ができないものもあります。